정렬이란?
정렬(Sort)은 대상이 되는 자료를 어떤 키 값에 따라 오름차순이나 내림차순으로 재배치하는 것을 의미한다.
정렬의 종류 및 분류

내부정렬: 정렬하고자 하는 자료를 주 메모리에 모두 가져다 놓고 정렬하는 방식으로, 자료의 양이 적을 떄 사용하며 정렬 속도가 빠르다.
외부정렬: 정렬하고자 하는 자료를 보조 기억 공간에 두고 일부분씩 주 메모리로 가져가 병합하여 정렬하는 방식으로, 자료의 양이 많을 때 사용한다.
정렬알고리즘은 선택 시 고려 다음 사항들을 고려해야 한다.
1. 초기 입력 자료의 배열 상태
2. 입력 자료의 양
3. 키 값들의 분포 상태
3. 소요 공간 및 작업 시간
4. 정렬에 필요한 기억 공간의 크기
5. 자료에 대한 액세스 빈도
내부정렬(Internal Sort)
1) 삽입정렬(Insertion Sort)
대상 자료가 일부 정렬되어 있을 떄 유리한 정렬 방식으로 선택(기준)된 키 값을 앞쪽 자료들의 키 값과 비교하여 자신의 위치를 찾아 삽입하여 정렬시키는 방식이다.
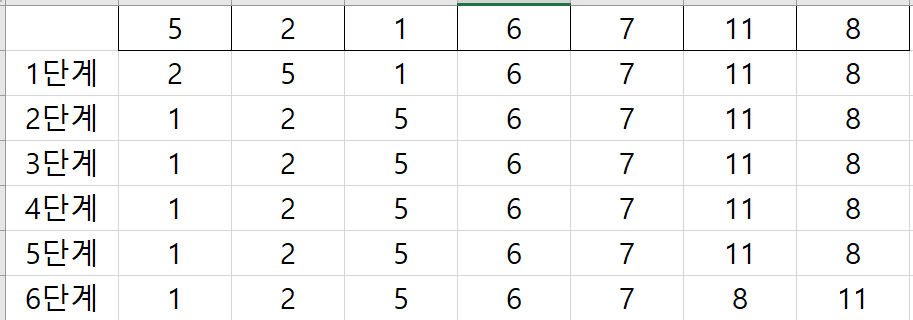
2) 셸 정렬 (Shell Sort)
매개 변수를 설정한 다음 데이터를 모아 매개 변수 간격만큼의 부파일을 만든 다음 그 매개 변수의 간격을 감소시키면서 정렬하는 방식으로 삽입 정렬의 확장된 개념이다.
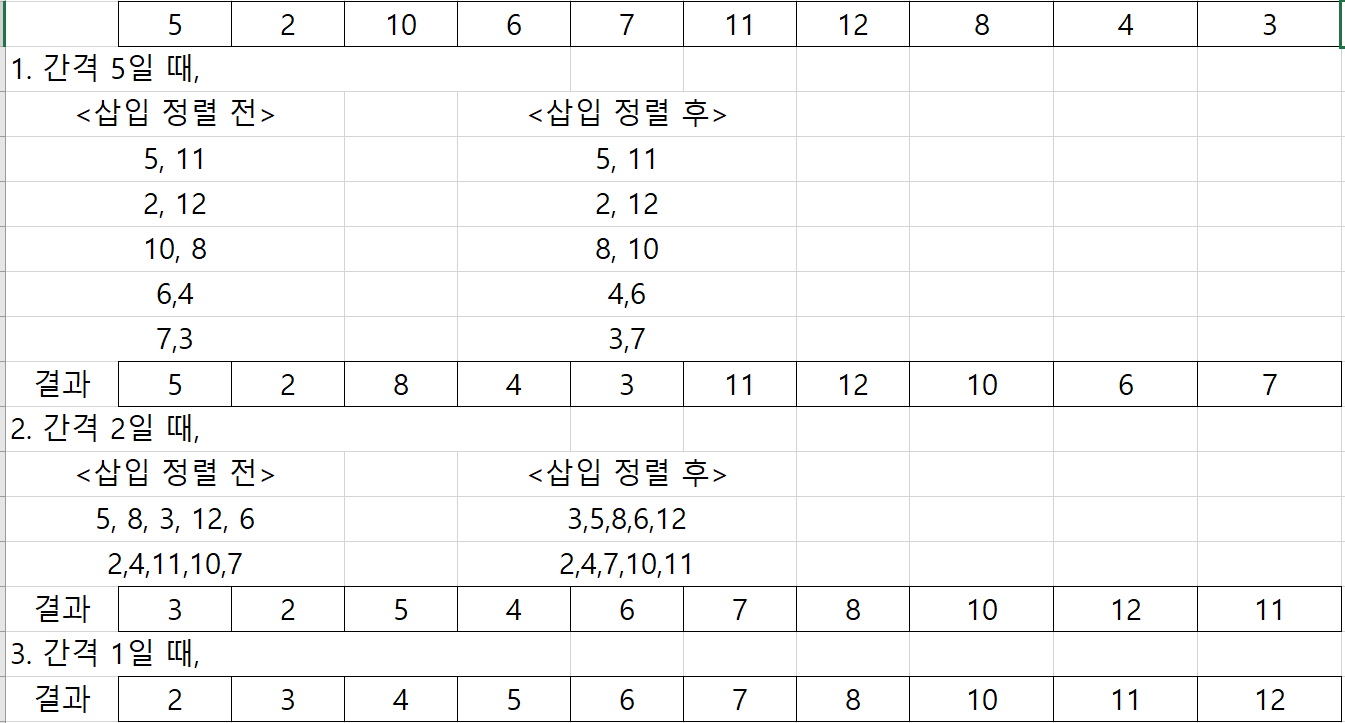
처음에 설정된 간격 (매개 변수) 만큼 숫자들을 정렬한다. 그런 다음, 간격 (매개변수 5>2로 감소)을 줄이면서, 최종적으로 마지막 1이 될때까지 정렬을 하면 순차적으로 정리된것을 확인할 수 있다.
3) 선택 정렬(Selection Sort)
전체 자료 중 작은 (혹은 큰 것) 키 값을 찾아 선택(기준)된 위치의 자료와 교환하여 정렬하는 방식이다.

전체 자료 중에서 가장 작은 1의 값이 처음 선택된 5(기준)와 위치가 교환이 되면서 1단계가 출력되었다. 그 다음은 2단계로 가면서 두번째 자리에 있던 4가 다음으로 작은 값 2와 교체 되었다. 3단계에서는 교환할 값이 없어서 그대로고, 4단계에서는 네 번쨰 자리인 4와 5가 교환되었다.이런식으로 순차적으로 반복을 하다가 마지막까지 도달한 것을 확인할 수 있다.
4) 버블 정렬(Bubble Sort)
인접키와 비교하면서 교환하여 정렬하되 단계뼐로 수행하면서 각 단계 수행 중 교환이 일어나지 않으면 정렬이 완료된 것이므로 더 이상의 단계를 수행하지 않고 종료시켜 정렬을 완료시키는 방법이다.

가장 처음 11과 2를 비교한다. 11이 더크니 뒤로 간다. 11과 10을 비교한다. 11이 크니 뒤로간다. 11과 1을 비교한다. 11이 크니 뒤로 간다.이런식으로 1단계에서 11이 가장 뒤로 가게 된다.
2단계에서는 2와 10을 비교한다. 10이 크니 뒤로간다. 10과 1을 비교한다. 10이 크니 뒤로간다. 10과 7을 비교한다. 10이 크니 뒤로간다. 10과 5를 비교한다. 10이 크니 뒤로 간다. 10과 3을 비교한다.10이 크니 뒤로간다. 10과 11을 비교한다. 11이 더 크니 멈춘다.
3단계에서는 2와 1을 비교한다.2가 더 크니 뒤로 간다. 7과 5를 비교한다. 7이 더 크니 뒤로간다.7과 3을 비교한다. 7이 더크니 뒤로간다. 7과 10을 비교한다. 10이 더 크니 멈춘다.
4단계에선 1과 2를 비교했을떄 변화가 없다. 2와 5도 변화가 없다. 5와 3을 비교한다. 5가 더 크다. 5가 뒤로 간다. 끝난다.
5, 6, 단계에서는 멈춘다.
5) 퀵정렬 (Quick Sort)
첫 번째 데이터를 중간 값으로 설정하고 그 중간 값을 대상 자료 중 적당한 위치에 위치시켜 대상 자료를 부분적으로 나누어 가면서 되부름 방식으로 반복 분류시켜 정렬하는 방식이다. 따라서 이 정렬방식은 이미 정렬되어 있는 자료를 정렬할 떄는 최악의 경우가 되어 복잡해진다.
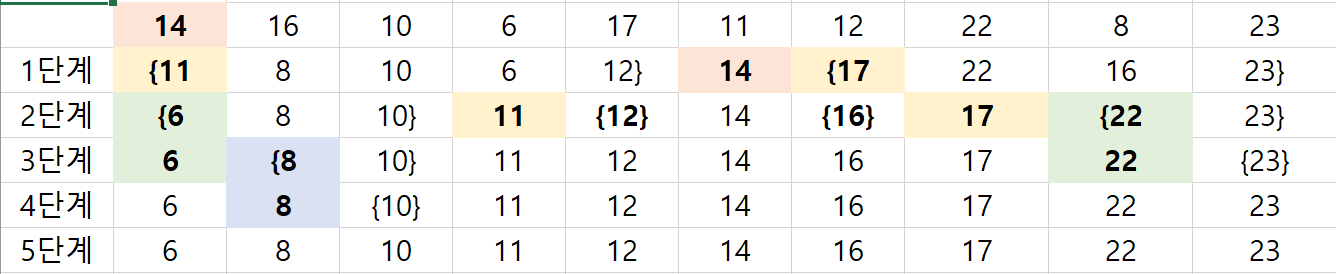
처음 값이 중간 값이 되어 정렬을 진행한다. 그럼 이제 각 중괄호 안에 있는 첫 값들이 다시 또 중간값이 되어 정렬을 한다. 그렇게 정렬을 하다가 중간값이 가장 앞에 올때 까지 멈춘다.
6) 힙 정렬(Heap Sort)
완전 이진 트리(Complete Binary Tree)인 오더드 트리(Ordered Tree) 형태로 데이터를 저장하고 트리 액세스 알고리즘에 의해 부노드가 자노드보다 크게 되도록 구성하는데, 첫 번쨰 구성된 형태를 초기 Heap 상태라고 한다. 이 초기 Heap 상태에서 근노드를 맨 마지막으로 이동시켜 대상 개수를 하나씩 줄여 나가면서 정렬하는 방식이다.
7) 이진 병합 정렬(2-Way Merge Sort)
두 개의 키들을 한 쌍으로 하여 각 쌍에 대하여 순서를 정하고 나서 순서대로 정렬된 각 쌍의 키들을 병합하여 하나의 정렬된 서브 리스트로 만들어 최종적으로 하나의 정렬된 파일이 될때까지 반복하여 정렬하는 방식이다.
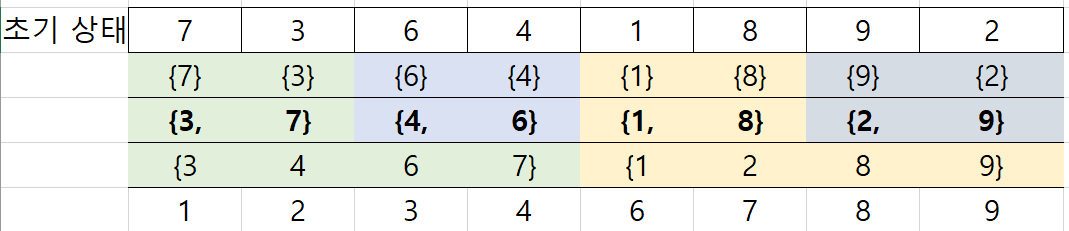
처음부터 숫자를 두개씩 쌍을 맞춘다. 각 쌍끼리 정렬을 한다. 그 후 정렬된 쌍들을 합쳐서 다시 또 정렬을 한다. 이를 반복한다. 처음엔 두개 씩 정렬> 네개 씩 정렬> 8개 씩 정렬 되는 것을 확인할 수 있다.
8) 버킷 정렬(Bucket Sort)
기수 정렬(Radix Sort), 버킷 정렬(Bucket Sort)은 정렬할 데이터의 기수 값에 따라 분배하여 정렬하는 방식으로 여분의 기억 공간이 많이 필요하다.

1단계
먼저 1의 단위로 Stack이 생성되고, 초기 값들의 끝자리에 따라 각 값을 집어 넣는다.
2단계
10 단위 Stack이 생성된다. 1단계에서 생성된 9의 단위부터 순차적으로 2단계에 집어 넣는다. (즉 제일 마지막 숫자부터 들어가게 된다.)
3단계
100의 단위 숫자가 없어서 종료되고 Stack 앞쪽 부터 꺼내서 나열한다.
참고자료
2019 정보처리기사 (출판사: 이기적)
'수업' 카테고리의 다른 글
| [20일차] 2021.01.06 네트워크 프로그래밍 (0) | 2021.01.06 |
|---|---|
| [19일차] 2021.01.05 (0) | 2021.01.05 |
| [17일차] 2021.01.04 (0) | 2021.01.04 |
| [2020.12.17] static (0) | 2020.12.17 |



